
Breve storia su come diventare miliardari con i dati delle persone
Come è nato e cresciuto Facebook

Chi mi conosce sa che vengo dal mondo startup. La prima domanda che un investitore vuole sapere in un pitch (il "pitch" è la presentazione di una startup) è la seguente: "Chi paga?", oppure "Qual è il modello di business?", che più o meno è la stessa cosa. Vediamo in questo articolo come ha fatto l'azienda più gratis del mondo, ovvero Facebook, a diventare un colosso con un prodotto apparentemente senza pagamenti.

Anno domini 2004, un giovane Mark Zuckerberg crea la propria creaturina nei dormitori di Harvard. Erano i primi anni in cui le persone cercavano connessioni su internet al di là delle email: nascevano i primi forum; c'era MySpace; qualcuno si ricorderà di Habbo Hotel. Lui sceglie il nome "Facebook" ("libro delle facce", se vogliamo tradurre) perché nei college americani è tradizione avere un annuario con le foto di chi ha frequentato la stessa istituzione; di fatto, prende la rete sociale degli alumni e la porta in digitale.
Foto dall'yearbook (annuario) di Tom Cruse, 1980 (fonte)
Da lì il social network prende piede verso il mondo intero, attraverso fruttuose tattiche di sviluppo del prodotto (se sei interessato a queste tematiche, ti consiglio di approfondire il Growth Hacking, pane quotidiano per le startup).
Ma da dove arriva il successo economico? Osserviamo cosa accade dentro Facebook (vale per qualsiasi social network):
c'è un prodotto ben fatto e gratuito che invoglia gli utenti a condividere dentro pensieri, link di canzoni, fotografie, ecc...
gli utenti immettono nella piattaforma i propri dati su chi sono (perché io devo essere rintracciabile dai miei amici) e su ciò che piace.
Molti siti si sono fermati al punto "1", mettono un bell'annuncio pubblicitario e guadagnano da quell'annuncio. Funziona a livello teorico, accade così anche nei quotidiani da secoli (se siete interessati ai quattrini dietro gli annunci pubblicitari dei quotidiani tradizionali, consiglio l'ascolto di questo podcast con Luca Sofri - direttore de Il Post - e Mario Calabresi - ex direttore di Repubblica). Ma a questo punto Mark Zuckeberg compie la magia.
Abbiamo detto che gli utenti mettono i propri dati personali nella piattaforma, inseriscono anche ciò che a loro piace. A questo punto nasce la scintilla di utilizzare quei dati per fare degli annunci mirati. Guardate questa diapositiva sul modello di business di Facebook, direttamente dal 2004:

"Pubblicità mirata", dal primo pitch del 2004 di Facebook (fonte)
Vi ricordo che siamo nel 2004, vent'anni fa, quando ancora l'Intelligenza Artificiale era tecnicamente poco accessibile. Eppure il nucleo è completo, gli ingredienti per il successo sono tutti presenti.
Qual è il vantaggio di mettere un annuncio su Facebook? Supponiamo che io gestisca un salone di bellezza, voglio fare pubblicità per vendere colpi di Sole. Una tecnica di marketing tradizionale è stampare dei volantini e lasciarli in giro nei palazzi. Chi prende i volantini? Più o meno tutti quelli del palazzo. Se lascio 20 volantini per condominio, il rischio è che li abbia stampati per persone non interessate, ad esempio pelate come il sottoscritto vivente.

A volte la dicitura "In questo condominio la pubblicità non è gradita" non basta
Il marketing tradizionale è dunque generalizzato (salvo alcuni casi), tra i destinatari ci sono persone potenzialmente interessate al mio prodotto e persone a cui invece non frega niente.
L'intuizione di Zuckeberg è dunque la seguente: dai dati degli utenti della mia piattaforma so chi è potenzialmente interessato ai colpi di sole e a trattamenti di bellezza. A questo punto l'annuncio del gestore del salone arriva direttamente ai potenziali interessati in modo molto mirato.
Non è un'intuizione di Zuckeberg soltanto, anche Google ha fatto grandi affari così. Avete presente i famosi "cookie", quelli che accettiamo quando visitiamo una pagina web senza sapere il perché? Servono esattamente a questo scopo, tracciare le preferenze di navigazione degli utenti e poter mandare loro annunci personalizzati.
Questo idillico matrimonio di persone che inseriscono gratuitamente i loro dati nella piattaforma ed esercenti che pagano per pubblicità mirate si incrina con l'avvento del Regolamento Generale della Protezione dei Dati, ovvero il GDPR, almeno in Europa. I pilastri fondamentali introdotti sono i seguenti:
le persone devono esprimere un consenso esplicitamente al trattamento dei dati;
le aziende sono responsabili di come questi dati sono trattati.
Il primo punto comporta trasparenza per l'utente: i dati vengono tracciati da anni, da molto prima dell'avvento del GDPR, solo che prima non era necessario dirlo pubblicamente. Il secondo comporta responsabilità sul trattamento di questi dati; ovvero, se li raccolgo, devo assicurarmi di tutelarli. Il regolamento è figlio della grande fuga di dati compiuta dalla società Cambridge Analytica ai danni di Facebook, vale la pena ricordare in soldoni la vicenda a distanza di 8 anni.
Cambridge Analytica è una società londinese che nel 2014 riesce a ottenere un profilo psicologico di circa 50 milioni di persone (per lo più americane) sfruttando una falla nel sistema di condivisione dati di Facebook. Vi ricordate quei test del tipo "Scopri che vegetale sei"? Bene, per fare quei test in realtà si "paga" donando i vostri dati Facebook alle società che li analizzano. Quei dati sono stati utilizzati dalle destre americane e inglesi per indirizzare le loro campagne elettorali: so dove le persone traggono informazioni, so di cosa le persone hanno paura, il trucco è fatto.

Veramente pensavate che quei test erano stati fatti così, tanto per?
Per ulteriori informazioni vi rimando a questa analisi de Il Post che ripercorre tutta la storia.
Sicuramente Facebook è cresciuto anche attraverso altre mosse, differenziando i propri prodotti e aggredendo fasce di mercato diverse (ad esempio, l'età media degli utenti su Instagram è diversa da quella di Facebook). Il filo comune rimane lo stesso di cui abbiamo parlato in questo articolo precedente: con i dati è possibile fare un sacco di soldi. Di quanti soldi parliamo? Pensate che nel 2022 è nata una bagarre tra Facebook ad Apple perché la seconda consentiva agli utenti di negare in toto l'utilizzo di dati personali (fonte), dall'annuncio in borsa la prima perse 240 miliardi in valore di mercato.
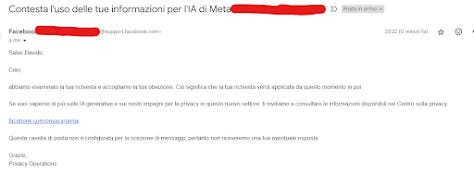
Tornando al tempo presente, i nostri dati oggi fanno gola non solo ai pubblicitari ma anche a chi studia Intelligenza Artificiale generativa. Ne parleremo in un prossimo articolo, tengo però a segnalarvi che dal 26 Giugno 2024 (quindi, tra due settimane, dal momento in cui sto scrivendo) i vostri dati saranno utilizzati in automatico da Meta per l'addestramento di AI. Perché in modo automatico? Perché l'informazione sarà inserita in un punto oscuro dei loro Termini & Condizioni. E' possibile però negare il consenso. La guida per farlo è la la seguente del prode Aranzulla. Vi lascio qui sotto il testo modello che ho condiviso qualche giorno fa su Instagram quando ho trattato del tema in un video, sentitevi liberi di fare copia e incolla per tutelarvi. A dimostrazione che il testo funziona, ecco degli screenshot di mail mandate direttamente da Facebook e da Instagram in cui hanno accettato la mia obiezione:
Il marketing tradizionale è dunque generalizzato (salvo alcuni casi), tra i destinatari ci sono persone potenzialmente interessate al mio prodotto e persone a cui invece non frega niente.
L'intuizione di Zuckeberg è dunque la seguente: dai dati degli utenti della mia piattaforma so chi è potenzialmente interessato ai colpi di sole e a trattamenti di bellezza. A questo punto l'annuncio del gestore del salone arriva direttamente ai potenziali interessati in modo molto mirato.
Non è un'intuizione di Zuckeberg soltanto, anche Google ha fatto grandi affari così. Avete presente i famosi "cookie", quelli che accettiamo quando visitiamo una pagina web senza sapere il perché? Servono esattamente a questo scopo, tracciare le preferenze di navigazione degli utenti e poter mandare loro annunci personalizzati.
Questo idillico matrimonio di persone che inseriscono gratuitamente i loro dati nella piattaforma ed esercenti che pagano per pubblicità mirate si incrina con l'avvento del Regolamento Generale della Protezione dei Dati, ovvero il GDPR, almeno in Europa. I pilastri fondamentali introdotti sono i seguenti:
le persone devono esprimere un consenso esplicitamente al trattamento dei dati;
le aziende sono responsabili di come questi dati sono trattati.
Il primo punto comporta trasparenza per l'utente: i dati vengono tracciati da anni, da molto prima dell'avvento del GDPR, solo che prima non era necessario dirlo pubblicamente. Il secondo comporta responsabilità sul trattamento di questi dati; ovvero, se li raccolgo, devo assicurarmi di tutelarli. Il regolamento è figlio della grande fuga di dati compiuta dalla società Cambridge Analytica ai danni di Facebook, vale la pena ricordare in soldoni la vicenda a distanza di 8 anni.
Cambridge Analytica è una società londinese che nel 2014 riesce a ottenere un profilo psicologico di circa 50 milioni di persone (per lo più americane) sfruttando una falla nel sistema di condivisione dati di Facebook. Vi ricordate quei test del tipo "Scopri che vegetale sei"? Bene, per fare quei test in realtà si "paga" donando i vostri dati Facebook alle società che li analizzano. Quei dati sono stati utilizzati dalle destre americane e inglesi per indirizzare le loro campagne elettorali: so dove le persone traggono informazioni, so di cosa le persone hanno paura, il trucco è fatto.

Veramente pensavate che quei test erano stati fatti così, tanto per?
Per ulteriori informazioni vi rimando a questa analisi de Il Post che ripercorre tutta la storia.
Sicuramente Facebook è cresciuto anche attraverso altre mosse, differenziando i propri prodotti e aggredendo fasce di mercato diverse (ad esempio, l'età media degli utenti su Instagram è diversa da quella di Facebook). Il filo comune rimane lo stesso di cui abbiamo parlato in questo articolo precedente: con i dati è possibile fare un sacco di soldi. Di quanti soldi parliamo? Pensate che nel 2022 è nata una bagarre tra Facebook ad Apple perché la seconda consentiva agli utenti di negare in toto l'utilizzo di dati personali (fonte), dall'annuncio in borsa la prima perse 240 miliardi in valore di mercato.
Tornando al tempo presente, i nostri dati oggi fanno gola non solo ai pubblicitari ma anche a chi studia Intelligenza Artificiale generativa. Ne parleremo in un prossimo articolo, tengo però a segnalarvi che dal 26 Giugno 2024 (quindi, tra due settimane, dal momento in cui sto scrivendo) i vostri dati saranno utilizzati in automatico da Meta per l'addestramento di AI. Perché in modo automatico? Perché l'informazione sarà inserita in un punto oscuro dei loro Termini & Condizioni. E' possibile però negare il consenso. La guida per farlo è la la seguente del prode Aranzulla. Vi lascio qui sotto il testo modello che ho condiviso qualche giorno fa su Instagram quando ho trattato del tema in un video, sentitevi liberi di fare copia e incolla per tutelarvi. A dimostrazione che il testo funziona, ecco degli screenshot di mail mandate direttamente da Facebook e da Instagram in cui hanno accettato la mia obiezione:
Ecco il testo della lettera:
Oggetto: Negazione categorica dell'uso dei miei dati per l'addestramento di modelli di Intelligenza Artificiale
Alla cortese attenzione di Meta Platforms, Inc.,
Con la presente, nego in maniera categorica, inderogabile, assoluta e senza possibilità di interpretazione il diritto di Meta Platforms, Inc. di utilizzare i miei dati per l'addestramento di modelli di Intelligenza Artificiale.
In particolare, specifico quanto segue:
1. *Definizione di "Dati"*: Per "dati" intendo qualsiasi informazione personale o identificabile che io, utente, metta a disposizione sulle piattaforme di Meta. Questo include, ma non si limita a:
- Dati personali (nome, data di nascita, indirizzo, contatti, ecc.).
- Dati relativi alle mie preferenze (like, interessi, post condivisi, ecc.).
- Metadati di navigazione (orari di accesso, frequenza delle visite, ecc.).
- Click e interazioni.
- Contenuti caricati, come fotografie, registrazioni vocali, video e qualsiasi altra forma di espressione o input sulle piattaforme di Meta (includendo, ma non limitandomi a, Facebook, Instagram, Threads, WhatsApp e altre piattaforme attuali o future).
2. *Definizione di "Intelligenza Artificiale"*: Per "Intelligenza Artificiale" intendo qualsiasi modello di apprendimento automatico. Questo include, ma non si limita a:
- Algoritmi di apprendimento supervisionato e non supervisionato.
- Modelli di apprendimento profondo (deep learning).
- Modelli generativi, come i modelli di linguaggio GPT (Generative Pre-trained Transformer), inclusi ma non limitati a Llama, ChatGPT, DALL-E, e simili.
- Modelli di riconoscimento delle immagini e video.
- Sistemi di raccomandazione e personalizzazione dei contenuti.
- Modelli predittivi di qualsiasi tipo.
Nel caso dovessi scoprire che i miei dati sono stati utilizzati per l'addestramento di Intelligenza Artificiale in qualsiasi momento (sia nel passato più remoto, nel presente o nel futuro), mi riservo il diritto di intraprendere azioni legali per tutelare la mia privacy e i miei diritti.
Chiedo che questa mia esplicita negazione venga registrata e rispettata immediatamente, senza eccezioni.
Cordialmente,
[Il tuo nome]